
22. 12. 2023
The most popular higher-order functions are map, filter, and reduce. We all use them since we think that syntax is much better and it is even faster to write them than the old way for-in loop. But is it really true? Have you ever thought about the performance of these built-in functions? They are built-in so naturally, they should be better, right? ???? Let’s dive into these functions together and uncover the truth ????.
Preconditions
- Data of size 10 000 000 elements
- Each test case was run 30x
- Median was used as a representation of each test case, not average, just to be sure that the result is not influenced by outliers
Data
This is what the data looks like: there are two arrays. One is the fahrenheit array, which is a 1D array of uniformly distributed random numbers from range <32.0;113.0> and the next array, fahrenheits, which is a 2D array of arrays of a uniformly distributed random number from range <32.0;113.0>.
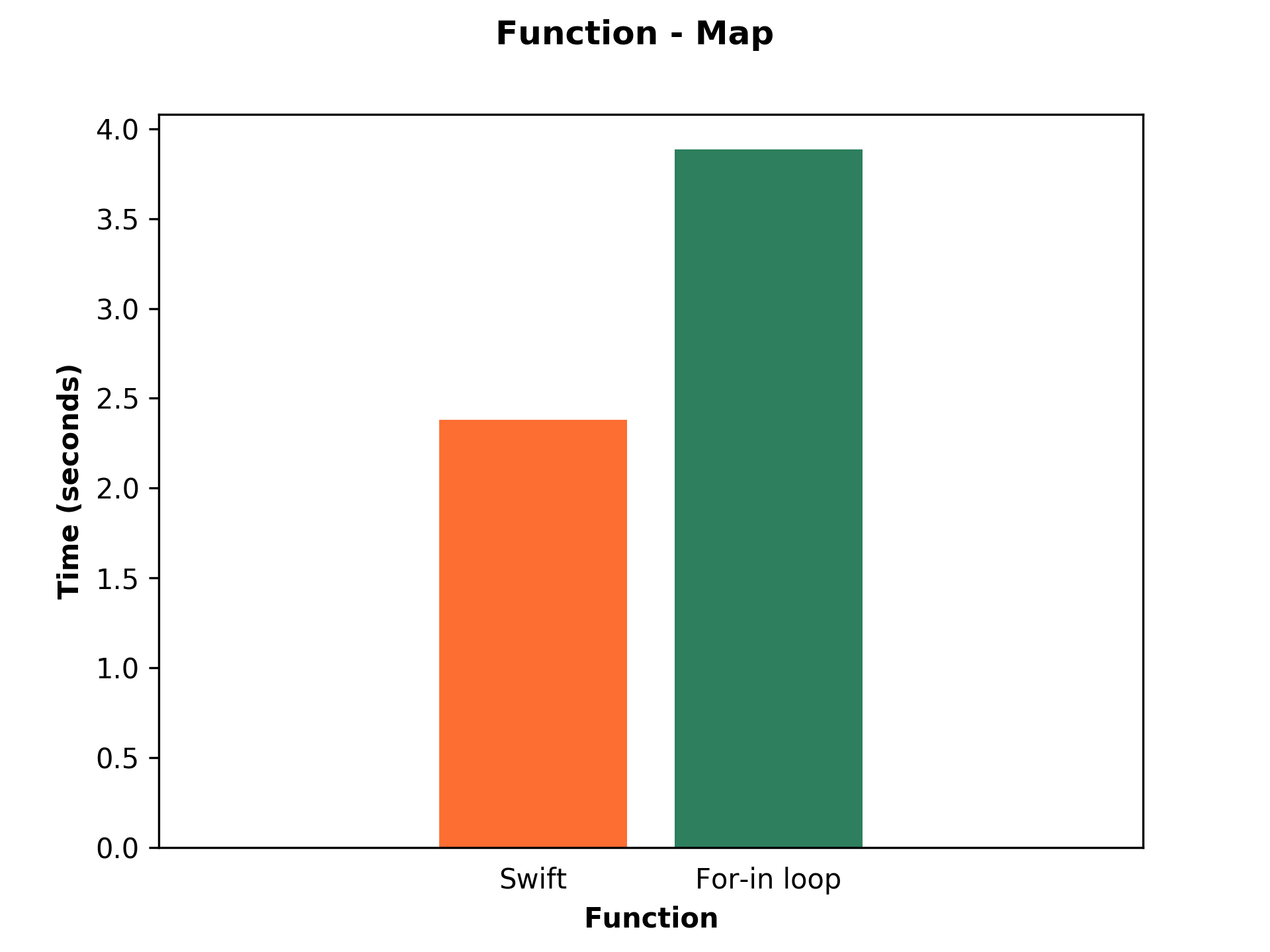
Function: Map
Let’s start with a simple example. We have the fahrenheit array and we want to convert each its element to degree Celsius. We are going, therefore, to compare the performance of the map function with a for-in loop.
Performance
As we can see in the picture, the built-in map function is much faster than the for-in loop. To be precise, it is 1.63x faster. There is no doubt that we should use a built-in map function.
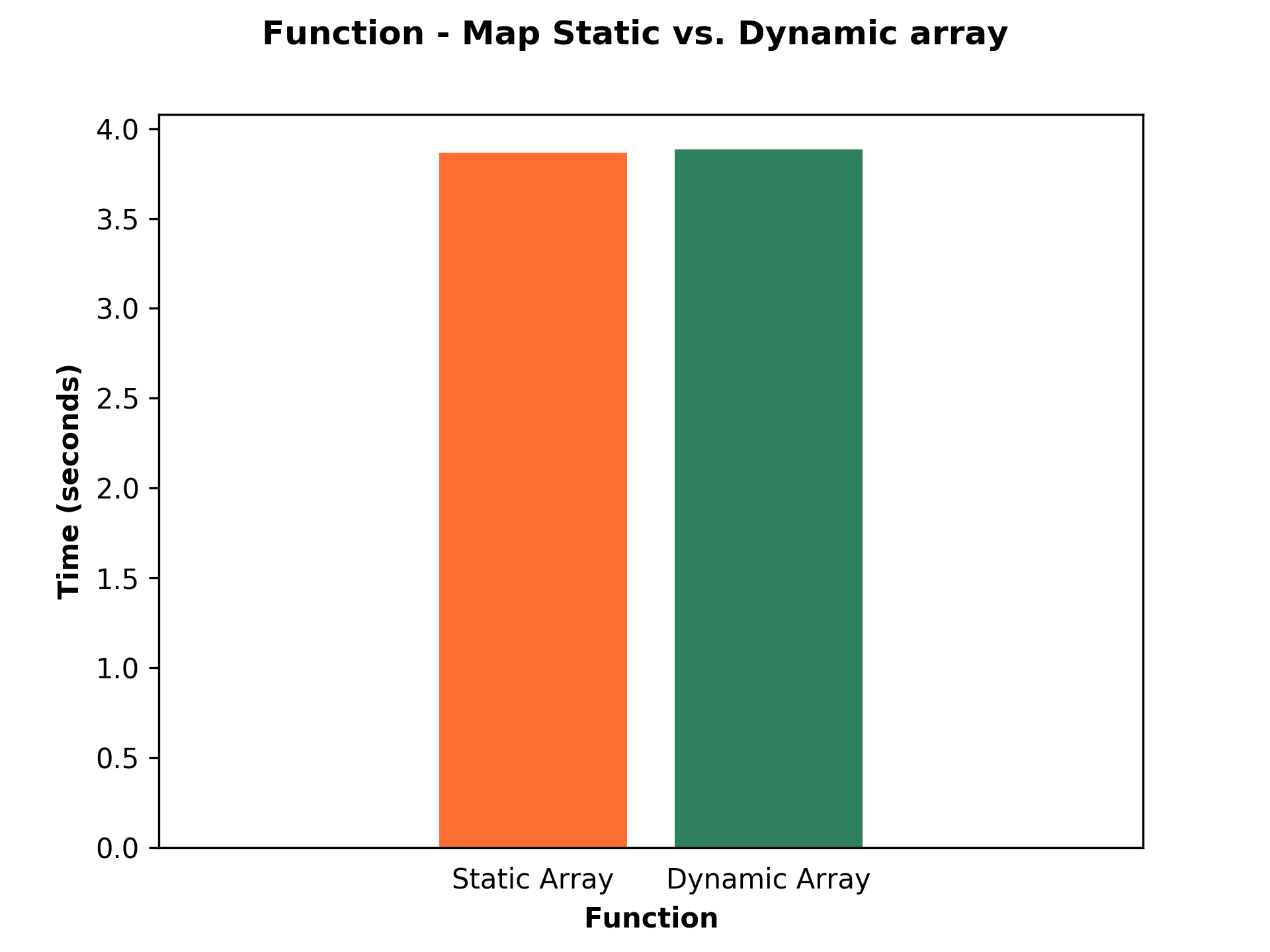
Static vs. dynamic array
I did not allocate the array with predefined size because there is no difference between the performance of a static and dynamic allocated array. I performed a quick test and here is the result. It is a little bit surprising. It may be the topic for the next article ????.
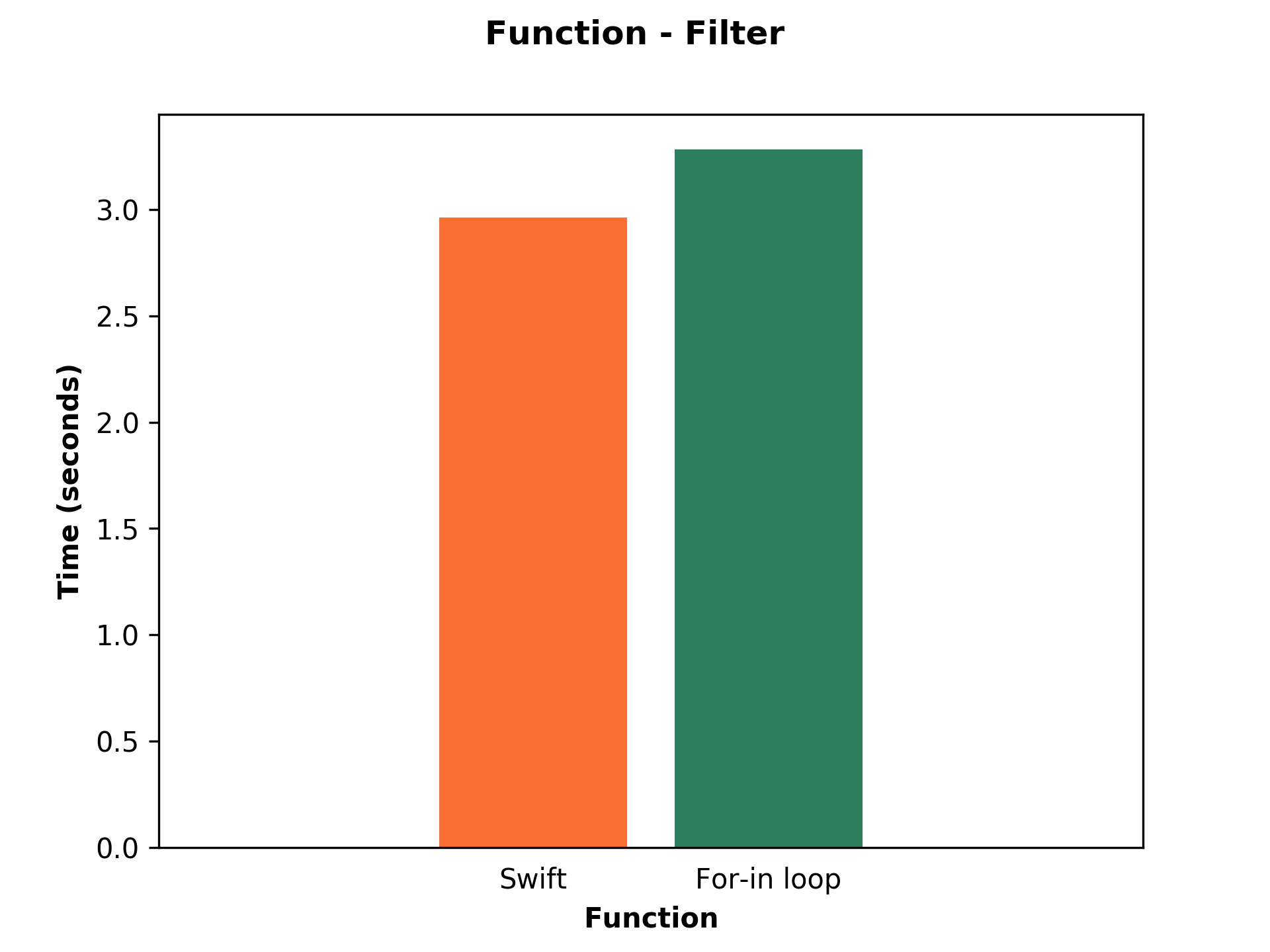
Function: Filter
The next function is a filter. So let’s filter cold degrees.
Why I do call them cold? I consider temperature less than or equal to 20 degrees Celsius (68 degrees Fahrenheit) to be cold and this is the reason why I named the variable colds.
Performance
The difference between a built-in filter function and a for-in loop is not so obvious in this case. The build-in function is slightly faster (1.11x) than for-in loop. Anyway, it is still faster, so it makes sense to use it.
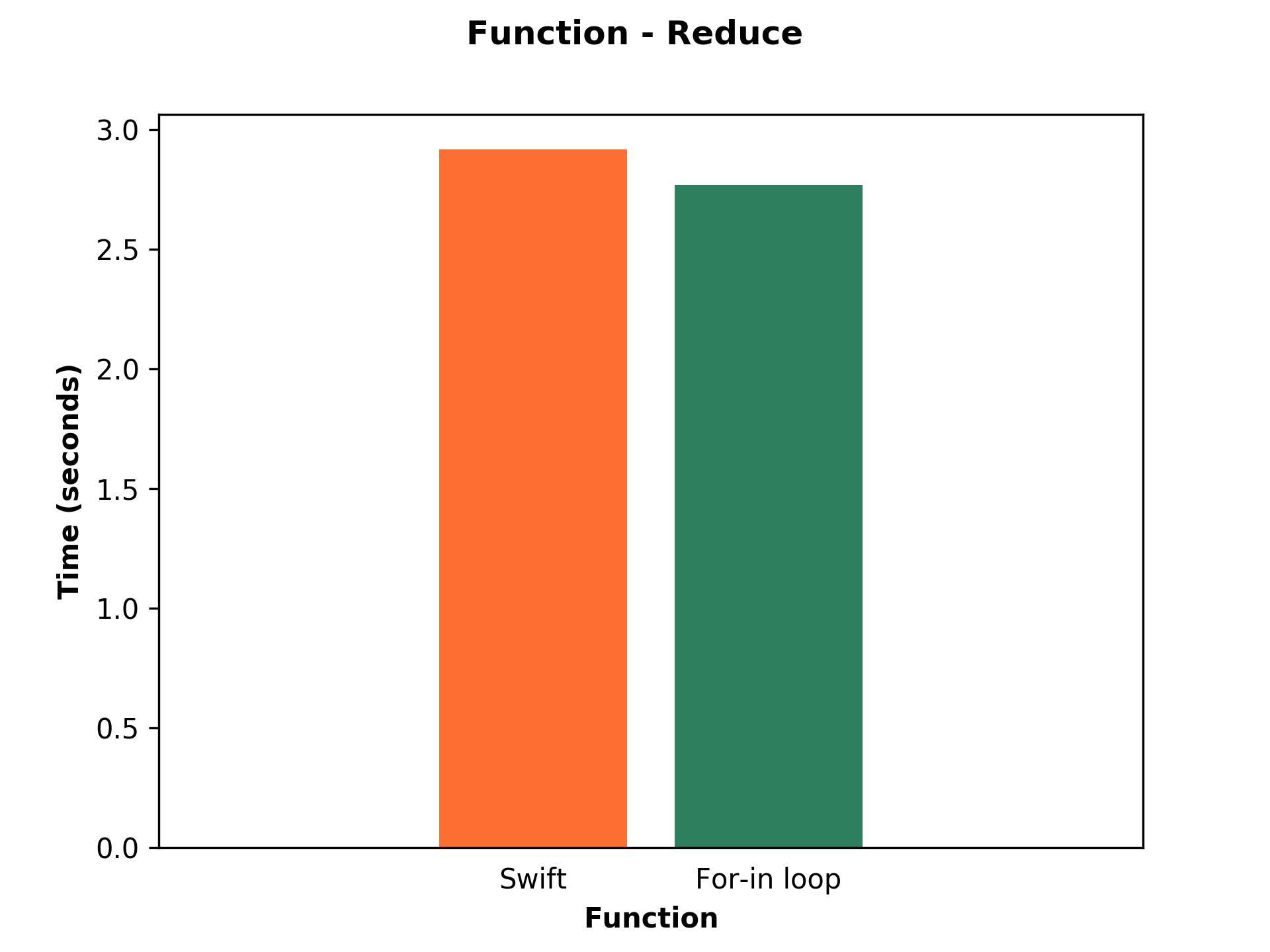
Function: Reduce
The last function is reduce. For this purpose, let’s add all numbers together. For example, we can use the result to compute the average temperature.
Performance
The result is a little bit surprising. The built-in reduce function is slightly slower than the for-in loop. Custom for-in loop reduce is 1.05x faster.
Function: FlatMap
Before we look at function chaining, let’s compare flatMap function with a for-in loop. We have fahrenheits array of arrays of double and we want to make the array of double.
Performance
The result is very similar to reduce function. The built-in flatMap function is a little bit slower than the for-in loop. Custom for-in loop flatMap is 1.06x faster.

Chaining (map +filter+reduce)
It is time for more fun. As we have seen so far, built-in functions are faster or slightly slower than custom one for-in loop. Many times developers use the chaining function to get the result they want or need. Let’s say we want to convert degrees Fahrenheit to degrees Celsius, then filter colds temperature, then add all filtered numbers.
It means that in the beginning, we have fahrenheit array of numbers, then call map function, then call filter function, then call reduce function.
Performance
Ups, as we can see in the picture, there is a problem.
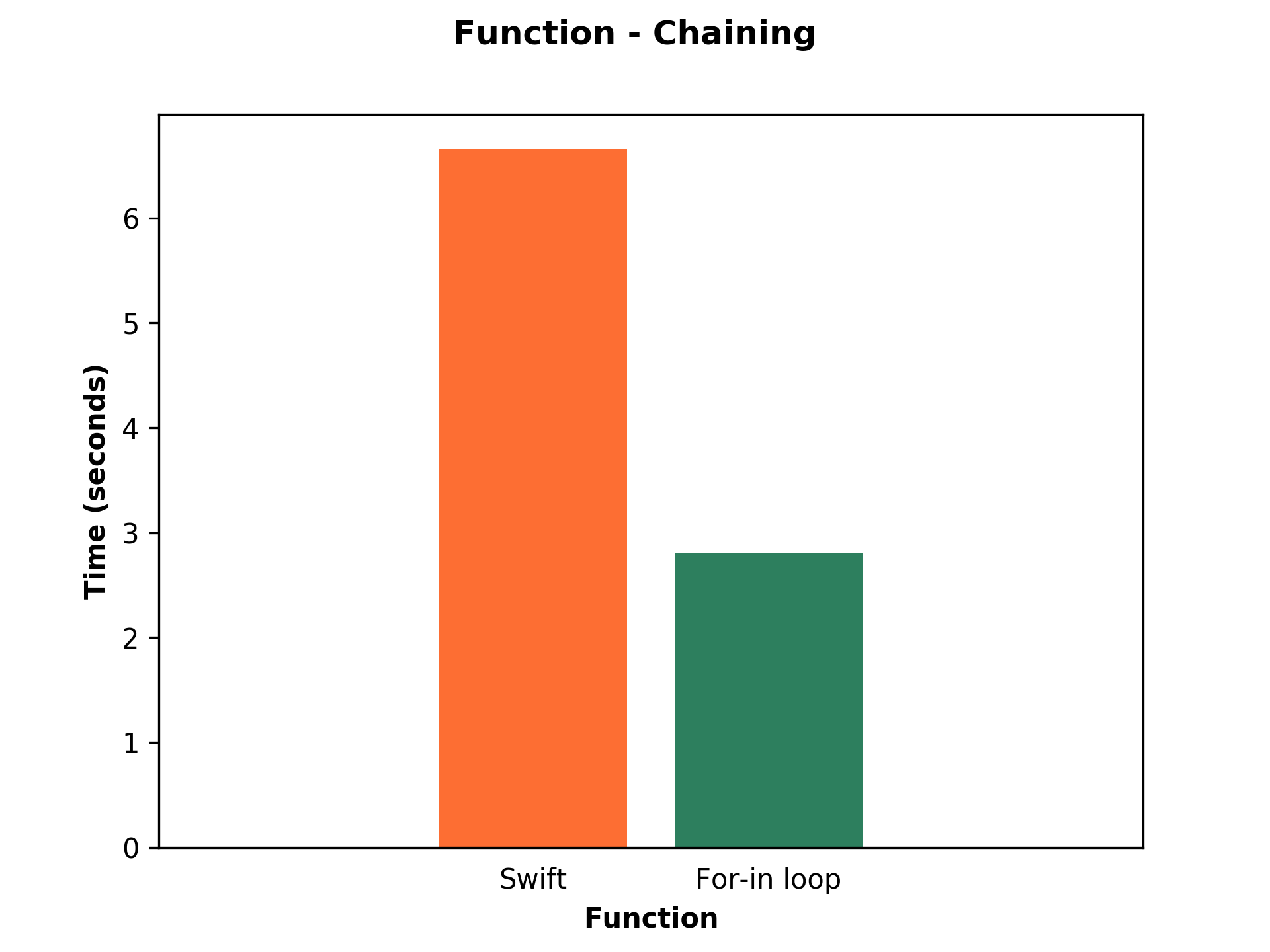
Built-in functions are way slower than the for-in loop. Custom for-in loop is 2.37x faster. When we use function chaining we should avoid built-in functions and write a custom solution with the for-in loop.
We may ask: “Why is it happening?”, “What is wrong with function chaining?”
I think it is obvious what is happening. When we use function chaining, we have to iterate over each result of the previous function. In computer science theory, there is the time complexity, which describes the amount of time it takes to run an algorithm.
In our case, in the beginning, we have fahrenheit array and we call map function. At this moment, the time complexity is O(n), linear time, where n is the size of fahrenheit array. Then we apply the result of map function to filter function. The time complexity of the filter function is O(n) as well. At this moment, the total time complexity is O(2n). The last step is reduce function. We apply the result of the filter function to reduce function. The time complexity of reduce function is again O(n), because big O notation is an upper bound on the growth rate of the function. In other words, in the worst case, the result of filter function can be O(n), which means nothing was filtered out and this result is used as input of reduce function. In the end, the time complexity is O(3n).
However, if we use a for-in loop we can do all necessary things (map. filter, reduce) we need in one for-in loop. Because of this fact, in the end, the time complexity of for-in loop is O(n).
Map, Filter, and Reduce in RxSwift
Just for comparison, let’s take a look at the same example in RxSwift. We’ll use map, filter, and reduce functions as we did in the previous example.
Performance
Oh, that is not good at all!
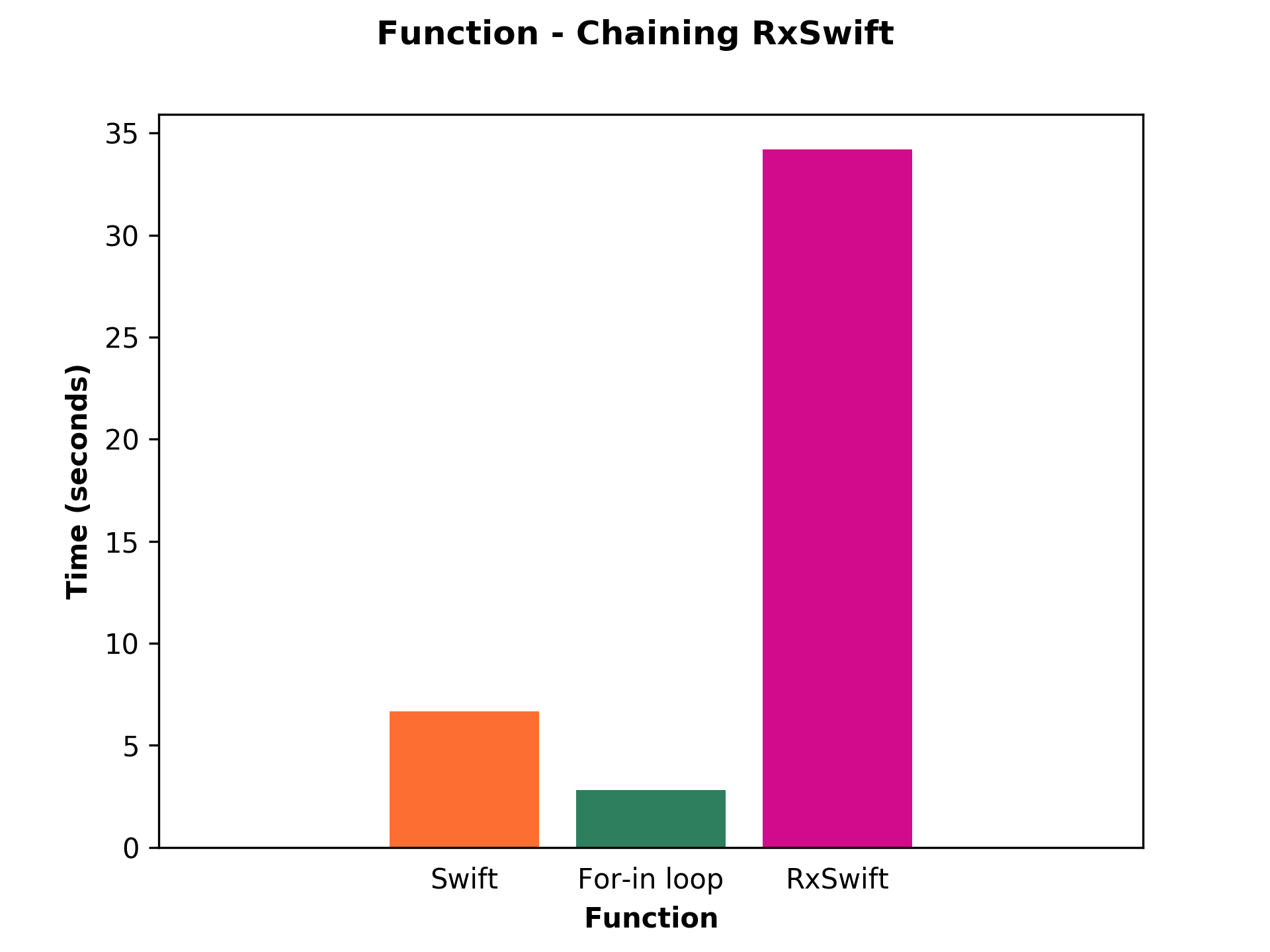
As we can see in the picture, RxSwift is way slower than built-in functions and for-in loop as well. The built-in functions solution is 5.14x faster than RxSwift and the for-in loop solution is 12.21x faster than RxSwift.
Please, do not use RxSwift when you need to work with a huge amount of data!
Conclusion
According to test cases, there is nothing wrong with using high-order functions when we do NOT need to chain them. The performance is way better (1.63x faster) when we use built-in map function or slightly better/worse when we use built-in filter/reduce.
If we want to chain high-order functions we should consider not using them and implementing them as a for-in loop solution. The performance is way better, 2.37x faster (in examples of this article) than built-in functions.
There is no need to always use modern elements, structures, or functions of a modern language just because the syntax looks better or everyone uses it. Time and space complexity is way more important than modern syntax and in the end, the fancy syntax does not make us better developers, even though we might think it does.
Do you need more detailed help? Book a consultation:
Let’s chat about it
Do you want more?
We share the world of software development on our Instagram. Join us 🙂

We also tend to look for Android dev (iOS as well), but there are also chances for a project manager or a tester. Send us an e-mail: [email protected].